손실(Loss) 함수를 정의하는 이유는
손실의 변화 정도를 살피기 위해서이다.
손실을 최소화하는 방향으로 목적 함수의 파라미터를 조절해나가야 한다는 목적을 갖고있기 때문에 손실의 변화 정도를 살피기 위하여 손실 함수를 정의하고 미분하여 기울기의 크기와 방향을 살피게 된다.
게다가 L2 손실로 손실 함수를 정의한다면, convex optimization problem이 되기 때문에 손쉽게 solution을 구할 수 있게 된다.

손실이 줄어드는 방향으로 model param이 이동한다. 이 때 이동 보폭은 정하기 나름이다. 특성이 많아서 차원이 높은 모델일 경우 똑같은 보폭이라 할지라도 발산할 가능성이 있다. 따라서 보폭을 줄여야 한다.
참고로 신경망은 그릇이 아니라 계란판처럼 생겼다. 따라서 초기값이 무엇이냐에 따라 결과가 달라지며 최솟값도 하나가 아닌 여러개다. 여기서는 단 하나의 최솟값만을 갖는 그릇 모양의 손실 함수라고 가정한다. 볼록 문제에는 기울기가 정확하게 0인 지점인 최소값이 하나만 존재한다. 이 최소값에서 손실 함수가 수렴한다.

손실을 줄이는 방향으로 가중치가 이동할 것이다.
모든 데이터셋에 대해 학습을 진행하여 최소값을 찾는 것은 비효율적이다. 몇 개의 데이터 샘플만으로 학습을 진행하여 최솟값을 찾는 것도 괜찮다는 것이 밝혀졌다. 그래서 mini batch 방식의 GD를 사용하면 된다.

머신러닝 모델이 반복을 통해 어떻게 손실을 줄이는지 알아보겠다.
반복 학습은 골무와 같이 숨겨진 물건을 찾는 아이들 놀이인 '핫 앤 콜드'와 비슷하다. 이 놀이에서 '숨겨진 물건'은 최적 모델이 된다. 처음에는 임의의 지점에서 시작해서('의 값은 0') 시스템이 손실 값을 알려줄 때까지 기다린다. 그런 다음 다른 값을 추정해서('의 값은 0.5') 손실 값을 확인한다. 이런 방식으로 가까워진다. 사실 이런 놀이는 제대로만 하면 점점 가까워지게 되어 있다. 이 게임의 진짜 요령은 최적의 모델을 가능한 한 가장 효율적으로 찾는 것이다.
다음 그림은 머신러닝 알고리즘이 모델을 학습하는 데 사용하는 반복적인 시행착오 과정을 보여준다.
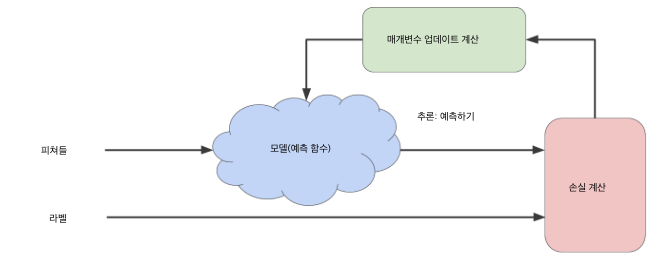
모든 알고리즘의 경우에 있어서와 같이 brute-force 방식은 비효율적이다.
손실 함수의 최적화된 지점을 찾기 위해 GD 방식이 적합하다.

경사하강법 알고리즘은 시작점에서 손실 곡선의 기울기를 계산한다. 간단히 설명하자면 기울기는 편미분의 벡터로서, 어느 방향이 '더 정확한지' 혹은 '더 부정확한지' 알려준다.
편미분의 벡터라는 말은 곧 여러 개의 각 특성들에 대한 각각의 기울기 또는 가중치를 의미한다. 그 각각의 가중치에 대해 미분을 한 것이 편미분이며 그것은 곧 벡터다.
'Artificial Intelligence > Machine Learning' 카테고리의 다른 글
| 기울기 (0) | 2018.12.23 |
|---|---|
| 손실(Loss) (0) | 2018.12.23 |
| 머신러닝을 위한 수학 (0) | 2018.12.23 |
| 머신러닝 알고리즘 cheet sheet (0) | 2018.12.23 |
| 머신러닝과 딥러닝의 주요한 차이 (0) | 2018.12.23 |